 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynFrame: Adaptive Reasoning-Driven Multimodal Framework with Dynamic Frame Augmentation for Complex Video Understanding
May 26, 2026Recent video multimodal large language models (MLLMs) increasingly couple step-by-step reasoning with on-demand visual evidence retrieval, allowing models to revisit relevant video segments during inference. However, two structural gaps remain in existing thinking-with-video systems. (i) Sampling density is not a learnable decision: existing methods may let the model decide where to look, but the per-window frame rate is largely fixed. As a result, fine-grained evidence is often recovered through repeated retrieval calls, which increases inference context length and training difficulty. (ii) Retrieval and answer generation are usually optimized with a single trajectory-level advantage, so the "where to look" tokens and the "how to answer" tokens receive the same credit even when one is correct and the other is not. To address these gaps, we present DynFrame, a framework that emits the temporal window and the sampling density as native tokens within a single autoregressive pass. This learnable span-density retrieval enables acquiring multi-granularity evidence with a single retrieval step. Based on the above tokenized retrieval interface, we further introduce Segment-Decoupled GRPO (SD-GRPO), which splits each rollout at the retrieval boundary and assigns role-specific token-level advantages, separately crediting the sampling decision and the answer. Trained on the curated DM-CoT-74k and DM-RL-45k, DynFrame-4B is competitive with strong 7B-8B baselines across six benchmarks (NExT-GQA, Charades-STA, ActivityNet-MR, Video-MME, MLVU, LVBench), and DynFrame-8B sets new state-of-the-art on most metrics. Code is available at https://github.com/zhangguanghao523/DynFrame.
Think When Needed: Adaptive Reasoning-Driven Multimodal Embeddings with a Dual-LoRA Architecture
May 14, 2026Multimodal large language models (MLLMs) have emerged as a powerful backbone for multimodal embeddings. Recent methods introduce chain-of-thought (CoT) reasoning into the embedding pipeline to improve retrieval quality, but remain costly in both model size and inference cost. They typically employ separate reasoner and embedder with substantial parameter overhead, and generate CoT indiscriminately for every input. However, we observe that for simple inputs, discriminative embeddings already perform well, and redundant reasoning can even mislead the model, degrading performance. To address these limitations, we propose Think When Needed (TWN), a unified multimodal embedding framework with adaptive reasoning. TWN introduces a dual-LoRA architecture that attaches reasoning and embedding adapters to a shared frozen backbone, detaching gradients at their interface to mitigate gradient conflicts introduced by joint optimization while keeping parameters close to a single model. Building on this, an adaptive think mechanism uses a self-supervised routing gate to decide per input whether to generate CoT, skipping unnecessary reasoning to reduce inference overhead and even improve retrieval quality. We further explore embedding-guided RL to optimize CoT quality beyond supervised training. On the 78 tasks of MMEB-V2, TWN achieves state-of-the-art embedding quality while being substantially more efficient than existing generative methods, requiring only 3-5% additional parameters relative to the backbone and up to 50% fewer reasoning tokens compared to the full generative mode.
PromptEcho: Annotation-Free Reward from Vision-Language Models for Text-to-Image Reinforcement Learning
Apr 14, 2026Reinforcement learning (RL) can improve the prompt following capability of text-to-image (T2I) models, yet obtaining high-quality reward signals remains challenging: CLIP Score is too coarse-grained, while VLM-based reward models (e.g., RewardDance) require costly human-annotated preference data and additional fine-tuning. We propose PromptEcho, a reward construction method that requires \emph{no} annotation and \emph{no} reward model training. Given a generated image and a guiding query, PromptEcho computes the token-level cross-entropy loss of a frozen VLM with the original prompt as the label, directly extracting the image-text alignment knowledge encoded during VLM pretraining. The reward is deterministic, computationally efficient, and improves automatically as stronger open-source VLMs become available. For evaluation, we develop DenseAlignBench, a benchmark of concept-rich dense captions for rigorously testing prompt following capability. Experimental results on two state-of-the-art T2I models (Z-Image and QwenImage-2512) demonstrate that PromptEcho achieves substantial improvements on DenseAlignBench (+26.8pp / +16.2pp net win rate), along with consistent gains on GenEval, DPG-Bench, and TIIFBench without any task-specific training. Ablation studies confirm that PromptEcho comprehensively outperforms inference-based scoring with the same VLM, and that reward quality scales with VLM size. We will open-source the trained models and the DenseAlignBench.
Denoising as Path Planning: Training-Free Acceleration of Diffusion Models with DPCache
Feb 26, 2026Diffusion models have demonstrated remarkable success in image and video generation, yet their practical deployment remains hindered by the substantial computational overhead of multi-step iterative sampling. Among acceleration strategies, caching-based methods offer a training-free and effective solution by reusing or predicting features across timesteps. However, existing approaches rely on fixed or locally adaptive schedules without considering the global structure of the denoising trajectory, often leading to error accumulation and visual artifacts. To overcome this limitation, we propose DPCache, a novel training-free acceleration framework that formulates diffusion sampling acceleration as a global path planning problem. DPCache constructs a Path-Aware Cost Tensor from a small calibration set to quantify the path-dependent error of skipping timesteps conditioned on the preceding key timestep. Leveraging this tensor, DPCache employs dynamic programming to select an optimal sequence of key timesteps that minimizes the total path cost while preserving trajectory fidelity. During inference, the model performs full computations only at these key timesteps, while intermediate outputs are efficiently predicted using cached features. Extensive experiments on DiT, FLUX, and HunyuanVideo demonstrate that DPCache achieves strong acceleration with minimal quality loss, outperforming prior acceleration methods by $+$0.031 ImageReward at 4.87$\times$ speedup and even surpassing the full-step baseline by $+$0.028 ImageReward at 3.54$\times$ speedup on FLUX, validating the effectiveness of our path-aware global scheduling framework. Code will be released at https://github.com/argsss/DPCache.
Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO
Feb 06, 2026Deploying GRPO on Flow Matching models has proven effective for text-to-image generation. However, existing paradigms typically propagate an outcome-based reward to all preceding denoising steps without distinguishing the local effect of each step. Moreover, current group-wise ranking mainly compares trajectories at matched timesteps and ignores within-trajectory dependencies, where certain early denoising actions can affect later states via delayed, implicit interactions. We propose TurningPoint-GRPO (TP-GRPO), a GRPO framework that alleviates step-wise reward sparsity and explicitly models long-term effects within the denoising trajectory. TP-GRPO makes two key innovations: (i) it replaces outcome-based rewards with step-level incremental rewards, providing a dense, step-aware learning signal that better isolates each denoising action's "pure" effect, and (ii) it identifies turning points-steps that flip the local reward trend and make subsequent reward evolution consistent with the overall trajectory trend-and assigns these actions an aggregated long-term reward to capture their delayed impact. Turning points are detected solely via sign changes in incremental rewards, making TP-GRPO efficient and hyperparameter-free. Extensive experiments also demonstrate that TP-GRPO exploits reward signals more effectively and consistently improves generation. Demo code is available at https://github.com/YunzeTong/TurningPoint-GRPO.
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
May 15, 2019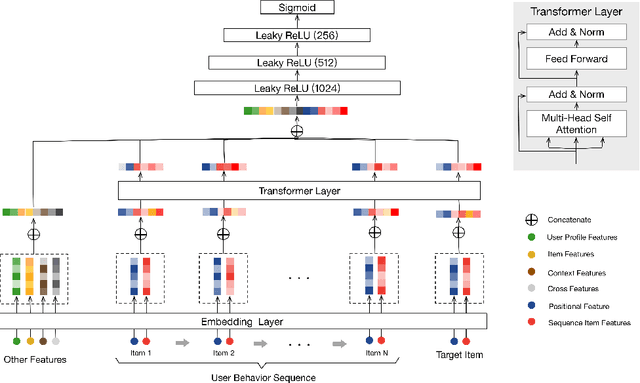



Deep learning based methods have been widely used in industrial recommendation systems (RSs). Previous works adopt an Embedding&MLP paradigm: raw features are embedded into low-dimensional vectors, which are then fed on to MLP for final recommendations. However, most of these works just concatenate different features, ignoring the sequential nature of users' behaviors. In this paper, we propose to use the powerful Transformer model to capture the sequential signals underlying users' behavior sequences for recommendation in Alibaba. Experimental results demonstrate the superiority of the proposed model, which is then deployed online at Taobao and obtain significant improvements in online Click-Through-Rate (CTR) comparing to two baselines.
Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
Apr 17, 2019

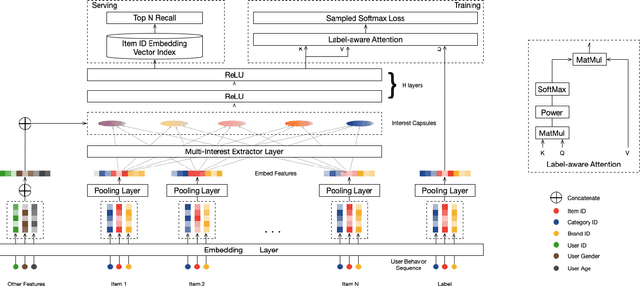

Industrial recommender systems usually consist of the matching stage and the ranking stage, in order to handle the billion-scale of users and items. The matching stage retrieves candidate items relevant to user interests, while the ranking stage sorts candidate items by user interests. Thus, the most critical ability is to model and represent user interests for either stage. Most of the existing deep learning-based models represent one user as a single vector which is insufficient to capture the varying nature of user's interests. In this paper, we approach this problem from a different view, to represent one user with multiple vectors encoding the different aspects of the user's interests. We propose the Multi-Interest Network with Dynamic routing (MIND) for dealing with user's diverse interests in the matching stage. Specifically, we design a multi-interest extractor layer based on capsule routing mechanism, which is applicable for clustering historical behaviors and extracting diverse interests. Furthermore, we develop a technique named label-aware attention to help learn a user representation with multiple vectors. Through extensive experiments on several public benchmarks and one large-scale industrial dataset from Tmall, we demonstrate that MIND can achieve superior performance than state-of-the-art methods for recommendation. Currently, MIND has been deployed for handling major online traffic at the homepage on Mobile Tmall App.
Multi-Level Deep Cascade Trees for Conversion Rate Prediction
Aug 29, 2018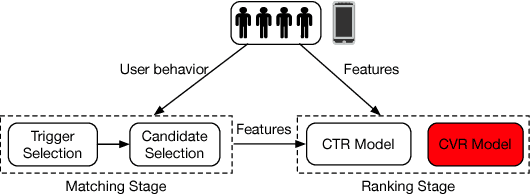

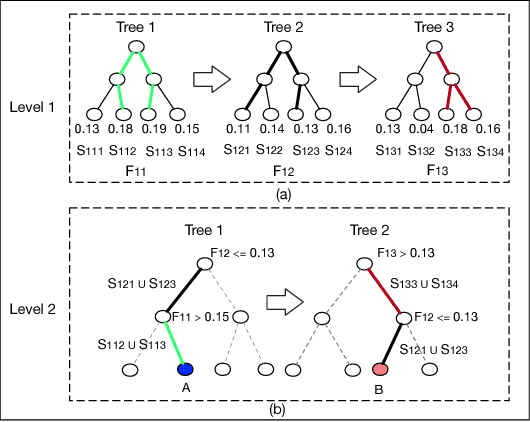

Developing effective and efficient recommendation methods is very challenging for modern e-commerce platforms (e.g., Taobao). In this paper, we tackle this problem by proposing multi-Level Deep Cascade Trees (ldcTree), which is a novel decision tree ensemble approach. It leverages deep cascade structures by stacking Gradient Boosting Decision Trees (GBDT) to effectively learn feature representation. In addition, we propose to utilize the cross-entropy in each tree of the preceding GBDT as the input feature representation for next level GBDT, which has a clear explanation, i.e., a traversal from root to leaf nodes in the next level GBDT corresponds to the combination of certain traversals in the preceding GBDT. The deep cascade structure and the combination rule enable the proposed ldcTree to have a stronger distributed feature representation ability. Moreover, we propose an ensemble ldcTree to take full use of weak and strong correlation features. Experimental results on off-line dataset and online deployment demonstrate the effectiveness of the proposed methods.
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
May 24, 2018

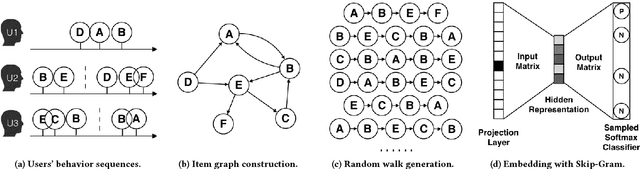
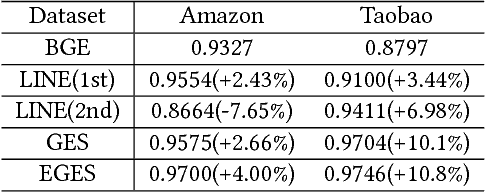
Recommender systems (RSs) have been the most important technology for increasing the business in Taobao, the largest online consumer-to-consumer (C2C) platform in China. The billion-scale data in Taobao creates three major challenges to Taobao's RS: scalability, sparsity and cold start. In this paper, we present our technical solutions to address these three challenges. The methods are based on the graph embedding framework. We first construct an item graph from users' behavior history. Each item is then represented as a vector using graph embedding. The item embeddings are employed to compute pairwise similarities between all items, which are then used in the recommendation process. To alleviate the sparsity and cold start problems, side information is incorporated into the embedding framework. We propose two aggregation methods to integrate the embeddings of items and the corresponding side information. Experimental results from offline experiments show that methods incorporating side information are superior to those that do not. Further, we describe the platform upon which the embedding methods are deployed and the workflow to process the billion-scale data in Taobao. Using online A/B test, we show that the online Click-Through-Rate (CTRs) are improved comparing to the previous recommendation methods widely used in Taobao, further demonstrating the effectiveness and feasibility of our proposed methods in Taobao's live production environment.